Complexidade computacional
A teoria da complexidade computacional é um ramo da teoria da computação em ciência da computação teórica e matemática que se concentra em classificar problemas computacionais de acordo com sua dificuldade inerente, e relacionar essas classes entre si. Neste contexto, um problema computacional é entendido como uma tarefa que é, em princípio, passível de ser resolvida por um computador (o que basicamente significa que o problema pode ser descrito por um conjunto de instruções matemáticas). Informalmente, um problema computacional consiste de instâncias do problema e soluções para essas instâncias do problema. Por exemplo, o teste de primalidade é o problema de determinar se um dado número é primo ou não. As instâncias deste problema são números naturais, e a solução para uma instância é sim ou não, dependendo se o número é primo ou não.
Um problema é considerado como inerentemente difícil se a sua solução requer recursos significativos, qualquer que seja o algoritmo usado. A teoria formaliza esta intuição através da introdução de modelos matemáticos de computação para estudar estes problemas e quantificar os recursos necessários para resolvê-los, tais como tempo e armazenamento. Outras medidas de complexidade também são utilizadas, tais como a quantidade de comunicação (usada em complexidade de comunicação), o número de portas em um circuito (usado na complexidade de circuito) e o número de processadores (usados em computação paralela). Um dos papéis da teoria da complexidade computacional é determinar os limites práticos do que os computadores podem e não podem fazer.
Campos intimamente relacionados com a ciência da computação teórica são a análise de algoritmos e a teoria da computabilidade. Uma distinção chave entre a análise de algoritmos e teoria da complexidade computacional é que a primeira é dedicada a analisar a quantidade de recursos necessários para um determinado algoritmo resolver um problema, enquanto o segundo faz uma pergunta mais geral sobre todos os possíveis algoritmos que podem ser usados para resolver o mesmo problema. Mais precisamente, ele tenta classificar os problemas que podem ou não podem ser resolvidos com os recursos devidamente restritos. Por sua vez, impondo restrições sobre os recursos disponíveis é o que distingue a complexidade computacional da teoria da computabilidade: a segunda pergunta que tipos de problemas podem, em princípio, ser resolvidos através de algoritmos.
Índice
1 Problemas Computacionais
1.1 Instâncias de Problema
1.2 Representando instâncias de problema
1.3 Problemas de decisão como linguagens formais
1.4 Problemas de função
1.5 Mensuração do tamanho de uma instância
2 Modelos de máquinas e medidas de complexidade
2.1 Máquina de Turing
2.2 Outros modelos de máquinas
2.3 Medidas de complexidade
2.4 Melhor, pior e caso médio de complexidade
2.5 Limites superior e inferior da complexidade dos problemas
3 Classes de complexidade
3.1 Definição de classes de complexidade
3.2 Importantes classes de complexidade
3.3 Teoremas de hierarquia
3.4 Redução
4 Importantes problemas em aberto
4.1 O problema P versus NP
4.2 Problemas em NP que não se sabe se pertencem a P ou a NP-completo
4.3 Separações entre outras classes de complexidade
5 Intratabilidade
6 Teoria da complexidade contínua
7 História
8 Ver também
9 Notas
10 Referências
10.1 Bibliografia
10.2 Surveys
11 Ligações externas
Problemas Computacionais |
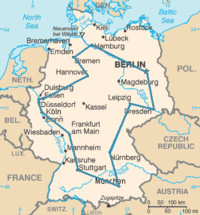
Um caminho ótimo para o cacheiro viajante passando pelas 15 maiores cidades da Alemanha. É o menor caminho entre as 43.589.145.600[nb 1] possibilidades de se visitar cada cidade exatamente uma única vez.
Instâncias de Problema |
Um problema computacional pode ser visto como uma coleção infinita de instâncias em conjunto com uma solução para cada instância. A sequência de entrada para um problema computacional é referido como uma instância do problema, e não deve ser confundido com o problema em si. Na teoria da complexidade computacional, um problema se refere à questão abstrata para ser resolvido. Em contraste, uma instância deste problema é uma expressão concreta, que pode servir como entrada para um problema de decisão. Por exemplo, considere o problema de teste de primalidade. A instância é um número (por exemplo, 10) e a solução é "sim" se o número é primo e "não" se for o contrário (neste caso "não"). Alternativamente, a instância é uma entrada especial para o problema, e a solução é a saída correspondente à entrada.
Para realçar ainda mais a diferença entre um problema e uma instância, considere a seguinte instância da versão de decisão do problema do caixeiro viajante: Existe um percurso de, no máximo, 2000 km de comprimento passando por todas as 15 maiores cidades da Alemanha? A resposta a esta determinada instância do problema é de pouca utilidade para a resolução de outras instâncias do problema, como pedir uma ida e volta através de todos os lugares de Milão cujo comprimento total é no máximo 10 km. Por esta razão, a teoria da complexidade aborda problemas computacionais e não instâncias particulares do problema.
Representando instâncias de problema |
Ao considerar problemas computacionais, uma instância de problema é uma cadeia sobre um alfabeto. Normalmente, o alfabeto é considerado como sendo o alfabeto binário (ou seja, o conjunto {0,1}), e, assim, as cadeias são bitstrings. Como em um computador do mundo real, objetos matemáticos que não são bitstrings devem ser devidamente codificados. Por exemplo, números inteiros podem ser representados em notação binária, e grafos podem ser codificados diretamente via suas matrizes de adjacência, ou por codificação de suas listas de adjacência em binário.
Apesar de algumas provas de complexidade-teórica de teoremas regularmente assumir alguma escolha concreta de codificação de entrada, tenta-se manter a discussão abstrata o suficiente para ser independente da escolha da codificação. Isto pode ser conseguido assegurando que diferentes representações possam ser transformadas em outra de forma eficiente.

Um problema de decisão tem apenas duas saídas possíveis, sim ou não (ou alternativamente 1 ou 0) para qualquer entrada.
Problemas de decisão como linguagens formais |
Problemas de decisão são um dos objetos de estudo centrais na teoria da complexidade computacional. Um problema de decisão é um tipo especial de problema computacional cuja resposta é sim ou não, ou alternativamente 1 ou 0. Um problema de decisão pode ser visto como uma linguagem formal, onde os membros da linguagem são instâncias cuja resposta é sim, e os não membros da linguagem são aquelas instâncias cuja saída é não. O objetivo é decidir, com a ajuda de um algoritmo, se uma dada sequência de entrada é um membro da linguagem formal em consideração. Se o algoritmo decidir este problema, ele retorna a resposta sim, diz-se que o algoritmo aceita a sequência de entrada, caso contrário, diz-se que rejeita a entrada.
Um exemplo de um problema de decisão é o seguinte. A entrada é um grafo arbitrário. O problema consiste em decidir se o dado grafo é conexo ou não. A linguagem formal associada a este problema de decisão é então o conjunto de todos os grafos conexos—obviamente, para obter uma definição precisa dessa linguagem, é preciso decidir como grafos são codificados como cadeias binárias.
Problemas de função |
Um problema de função é um problema computacional, onde uma única saída (de uma função total) é esperada para cada entrada, mas a saída é mais complexa do que a de um problema de decisão, isto é, não é apenas sim ou não. Exemplos notáveis incluem o problema do caixeiro viajante e o problema de fatoração de inteiros.
É tentador pensar que a noção de problemas de função é muito mais rica do que a noção de problemas de decisão. No entanto, o caso realmente não é esse, já que problemas de função podem ser reformulados como problemas de decisão. Por exemplo, a multiplicação de dois números inteiros pode ser expressa como o conjunto (a, b, c) tal qual a relação a × b = c descreve. Decidir se uma dada tripla é membro deste conjunto corresponde a resolver o problema da multiplicação de dois números.
Mensuração do tamanho de uma instância |
Para medir a dificuldade de resolver um problema computacional, pode-se desejar ver quanto tempo o melhor algoritmo necessita para resolver o problema. No entanto, o tempo de execução pode, em geral, depender da instância. Em particular, instâncias maiores exigirão mais tempo para resolver. Assim, o tempo necessário para resolver um problema (ou o espaço necessário, ou qualquer outra medida de complexidade) é calculado em função do tamanho da instância. Isso geralmente leva em consideração o tamanho da entrada em bits. A Teoria da Complexidade está interessada em como os tempos de execução de algoritmos crescem com um aumento no tamanho da entrada. Por exemplo, no problema de descobrir se um grafo é conectado, quanto tempo a mais leva para resolver um problema para um grafo com 2n vértices comparado ao tempo levado para um grafo com n vértices?
Se o tamanho da entrada é n, o tempo gasto pode ser expresso como uma função de n. Já que o tempo gasto em diferentes entradas de mesmo tamanho pode ser diferente, o pior caso em complexidade de tempo T(n) é definido como sendo o tempo máximo dentre todas as entradas de tamanho n. Se T(n) é um polinômio em n, então o algoritmo é dito ser um algoritmo de tempo polinomial. A tese de Cobham diz que um problema pode ser resolvido com uma quantidade factível de recursos se ele admite um algoritmo de tempo polinomial.
Modelos de máquinas e medidas de complexidade |
Máquina de Turing |

Uma representação artística de uma máquina de Turing
Uma máquina de Turing é um modelo matemático de uma máquina de computação em geral. É um dispositivo teórico que manipula símbolos contidos em uma tira de fita. Máquinas de Turing não pretendem ser uma tecnologia de computação na prática, mas sim uma experiência de pensamento que representa uma máquina de computação. Acredita-se que se um problema pode ser resolvido por um algoritmo, então existe uma máquina de Turing que resolve o problema. Na verdade, esta é a afirmação da tese de Church-Turing. Além disso, sabe-se que tudo o que pode ser computado em outros modelos de computação conhecido por nós hoje, como uma máquina RAM, Jogo da Vida de Conway, autômato celular ou qualquer linguagem de programação pode ser computado em uma máquina de Turing. Como as máquinas de Turing são fáceis de analisar matematicamente, e acredita-se que sejam tão poderosas quanto qualquer outro modelo de computação, a máquina de Turing é o modelo mais comumente usado em teoria da complexidade.
Muitos tipos de máquinas de Turing são usados para definir as classes de complexidade, tais como máquinas de Turing determinísticas, máquinas de Turing probabilísticas, máquinas de Turing não-determinísticas, máquinas de Turing quânticas, máquinas de Turing simétricas e máquinas de Turing alternadas. Todas elas são igualmente poderosas, em princípio, mas quando os recursos (tais como tempo e espaço) são limitados, algumas destas podem ser mais poderosas do que outras.
Uma máquina de Turing determinística é a máquina de Turing do tipo mais básico, que utiliza um conjunto fixo de regras para determinar suas ações futuras. Uma máquina de Turing probabilística é uma máquina de Turing determinística com um suprimento extra de bits aleatórios. A capacidade de tomar decisões probabilísticas muitas vezes ajuda algoritmos a resolverem problemas de forma mais eficiente. Algoritmos que usam bits aleatórios são chamados algoritmos probabilísticos. A máquina de Turing não-determinística é uma máquina de Turing determinística com uma característica adicional de não-determinismo, que permite que uma máquina de Turing tenha várias possíveis ações futuras a partir de um determinado estado. Uma maneira de entender o não-determinismo é visualizar os ramos da máquina de Turing como os vários caminhos computacionais possíveis a cada passo, e se ela resolve o problema em qualquer um desses ramos, diz-se ter resolvido o problema. Evidentemente, este modelo não pretende ser um modelo fisicamente realizável, é apenas uma máquina abstrata teoricamente interessante que dá origem a classes de complexidade particularmente interessantes. Por exemplo, veja algoritmo não-determinístico.
Outros modelos de máquinas |
Muitos modelos de máquinas diferentes do padrão de máquinas de Turing multi-fitas têm sido propostos na literatura, por exemplo, máquinas de acesso aleatório. Talvez surpreendentemente, cada um desses modelos pode ser convertido para outro, sem fornecer qualquer poder computacional extra. O consumo de tempo e memória desses modelos alternativos pode variar.[1] O que todos estes modelos têm em comum é que as máquinas funcionam de forma determinística.
No entanto, alguns problemas computacionais são mais fáceis de analisar em termos de recursos mais incomuns. Por exemplo, uma máquina de Turing não-determinística é um modelo computacional em que é permitido ramificar-se para verificar muitas possibilidades diferentes de uma só vez. A máquina de Turing não-determinística tem muito pouco a ver com a forma como nós queremos fisicamente computar algoritmos, mas a sua ramificação capta exatamente muitos dos modelos matemáticos que queremos analisar, de modo que o tempo não-determinístico é um recurso muito importante na análise de problemas computacionais.
Medidas de complexidade |
Para uma definição precisa do que significa resolver um problema utilizando uma determinada quantidade de tempo e espaço, um modelo computacional tal como a máquina de Turing determinística é utilizado. O tempo exigido por uma máquina de Turing determinística M na entrada x é o número total de transições de estado, ou etapas, que a máquina faz antes de parar e responder com a saída ("sim" ou "não"). Diz-se que a máquina de Turing M opera dentro do tempo f(n), se o tempo exigido por M em cada entrada de comprimento n é no máximo f(n). Um problema de decisão A pode ser resolvido em tempo f(n) se existe uma operação da máquina de Turing em tempo f(n) que resolve o problema. Como a teoria da complexidade está interessada em classificar problemas com base na sua dificuldade, definem-se conjuntos de problemas com base em alguns critérios. Por exemplo, o conjunto de problemas solucionáveis no tempo f(n) em uma máquina de Turing determinística é então indicado por DTIME(f(n)).
Definições análogas podem ser feitas para os requisitos de espaço. Embora o tempo e o espaço sejam os mais conhecidos recursos de complexidade, qualquer medida de complexidade pode ser vista como um recurso computacional. Medidas de complexidade são geralmente definidas pelos axiomas de complexidade de Blum. Outras medidas de complexidade utilizadas na teoria da complexidade incluem a complexidade de comunicação, a complexidade do circuito e a complexidade da árvore de decisão.
Melhor, pior e caso médio de complexidade |
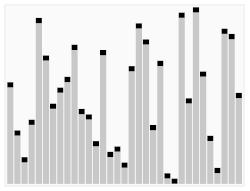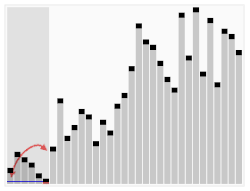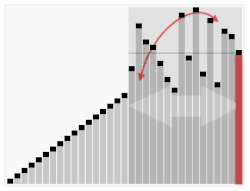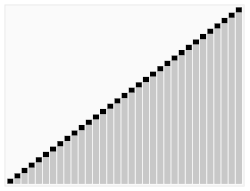
Visualização do algoritmo quicksort que tem no caso médio desempenho Θ(nlogn).{displaystyle Theta (nlog n).}

O melhor, o pior e o caso médio de complexidade referem-se a três maneiras diferentes de medir a complexidade de tempo (ou qualquer outra medida de complexidade) de entradas diferentes do mesmo tamanho. Uma vez que algumas entradas de tamanho n podem ser mais rápidas para resolver do que outras, definimos as seguintes complexidades:
- Complexidade no melhor caso: Esta é a complexidade de resolver o problema para a melhor entrada de tamanho n.
- Complexidade no pior caso: Esta é a complexidade de resolver o problema para a pior entrada de tamanho n.
- Complexidade no caso médio: Esta é a complexidade de resolver o problema na média. Essa complexidade só é definida com relação a uma distribuição de probabilidade sobre as entradas. Por exemplo, se todas as entradas do mesmo tamanho são consideradas terem a mesma probabilidade de aparecer, a complexidade do caso médio pode ser definida com relação à distribuição uniforme sobre todas as entradas de tamanho n.
Por exemplo, considere o algoritmo de ordenação quicksort. Isso resolve o problema de ordenar uma lista de inteiros que é dada como entrada. O pior caso é quando a entrada já está ordenada ou está em ordem inversa, e o algoritmo leva tempo O(n2) para este caso. Se assumirmos que todas as permutações possíveis da lista de entrada são igualmente prováveis, o tempo médio necessário para a ordenação é O(n log n). O melhor caso ocorre quando cada pivô divide a lista pela metade, também precisando tempo O(n log n).
Limites superior e inferior da complexidade dos problemas |
Para classificar o tempo de computação (ou recursos semelhantes, como o consumo de espaço), é necessário provar os limites superiores e inferiores sobre a quantidade mínima de tempo exigida pelo algoritmo mais eficiente para resolver um determinado problema. A complexidade de um algoritmo é geralmente entendida como a sua complexidade de pior caso, a menos que seja especificado o contrário. A análise de um determinado algoritmo cai sob o campo de análise de algoritmos. Para mostrar um limite superior T(n) sobre a complexidade de tempo de um problema, é necessário mostrar apenas que há um determinado algoritmo com tempo de funcionamento, no máximo, T(n). No entanto, provar limites inferiores é muito mais difícil, uma vez que limites inferiores fazem uma declaração sobre todos os possíveis algoritmos que resolvem um determinado problema. A frase "todos os algoritmos possíveis" inclui não apenas os algoritmos conhecidos hoje, mas qualquer algoritmo que possa ser descoberto no futuro. Para mostrar um limite inferior de T(n) para um problema requer mostrar que nenhum algoritmo pode ter complexidade de tempo menor do que T(n).
Limites superiores são geralmente indicados usando a notação O-grande, que desconsidera fatores constantes e termos menores. Isso faz com que os limites independam dos detalhes específicos do modelo computacional utilizado. Por exemplo, T(n) = 7n2 + 15n + 40, em notação O-grande seria escrito da seguinte forma T(n) = O(n2).
Limites inferiores são geralmente indicados usando a notação Ω
Classes de complexidade |
Definição de classes de complexidade |
Uma classe de complexidade é um conjunto de problemas de complexidade relacionados. As classes mais simples de complexidade são definidas pelos seguintes fatores:
- O tipo de problema computacional: Os problemas mais comumente utilizados são problemas de decisão. No entanto, classes de complexidade podem ser definidas com base em problemas de função, problemas de contagem, problemas de otimização, problemas de promessa, etc.
- O modelo de computação: O modelo mais comum de computação é a máquina de Turing determinística, mas muitas classes de complexidade são baseadas em máquinas de Turing não-determinísticas, circuitos Booleanos, máquinas de Turing quânticas, circuitos monótonos, etc.
- O recurso (ou recursos) que está sendo limitado e os limites: Essas duas propriedades são geralmente declaradas em conjunto, tais como "tempo polinomial", "espaço logarítmico", "profundidade constante", etc.
É claro, algumas classes de complexidade têm definições complexas que não se encaixam nesse quadro. Assim, uma classe de complexidade típica tem uma definição como a seguinte:
- O conjunto de problemas de decisão solúveis por uma máquina de Turing determinística dentro do tempo f(n). (Esta classe de complexidade é conhecida como DTIME(f(n))).
Mas limitar o tempo de computação acima por alguma função concreta f(n) muitas vezes produz classes de complexidade que dependem do modelo da máquina escolhida. Por exemplo, a linguagem {xx | x é uma sequência binária qualquer} pode ser resolvida em tempo linear em uma máquina de Turing multi-fitas, mas necessariamente exige tempo quadrático no modelo de máquinas de Turing single-fita. Se permitirmos variações no tempo polinomial em execução, a tese de Cobham-Edmonds afirma que "as complexidades do tempo em quaisquer dois modelos razoáveis e gerais de computação são polinomialmente relacionados" (Goldreich 2008, Chapter 1.2). Isto forma a base para a classe de complexidade P, que é o conjunto de problemas de decisão solúveis por uma máquina de Turing determinística dentro do tempo polinomial. O conjunto correspondente de problemas de função é FP.
Importantes classes de complexidade |

Uma representação da relação entre as classes de complexidade
Muitas classes de complexidade importantes podem ser definidas por limitando o tempo ou espaço usado pelo algoritmo. Algumas importantes classes de complexidade de problemas de decisão definidas desta maneira são as seguintes:
| Classe de complexidade | Modelo de computação | Limitação de recursos |
|---|---|---|
DTIME(f(n)) | Máquina de Turing Determinística | Tempo f(n) |
P | Máquina de Turing Determinística | Tempo poly(n) |
EXPTIME | Máquina de Turing Determinística | Tempo 2poly(n) |
NTIME(f(n)) | Máquina de Turing Não-Determinística | Tempo f(n) |
NP | Máquina de Turing Não-Determinística | Time poly(n) |
NEXPTIME | Máquina de Turing Não-Determinística | Tempo 2poly(n) |
DSPACE(f(n)) | Máquina de Turing Determinística | Espaço f(n) |
L | Máquina de Turing Determinística | Espaço O(log n) |
PSPACE | Máquina de Turing Determinística | Espaço poly(n) |
EXPSPACE | Máquina de Turing Determinística | Espaço 2poly(n) |
NSPACE(f(n)) | Máquina de Turing Não-Determinística | Espaço f(n) |
NL | Máquina de Turing Não-Determinística | Espaço O(log n) |
NPSPACE | Máquina de Turing Não-Determinística | Espaço poly(n) |
NEXPSPACE | Máquina de Turing Não-Determinística | Espaço 2poly(n) |
Acontece que PSPACE = NPSPACE e EXPSPACE = NEXPSPACE pelo teorema de Savitch.
Outras classes de complexidade importantes incluem BPP, ZPP e RP, que são definidas usando máquinas de Turing probabilística; AC e NC, que são definidas usando circuitos booleanos e BQP e QMA, que são definidas usando máquinas de Turing quânticas. #P é uma importante classe complexidade de problemas de contagem (que não são problemas de decisão). Classes como IP e AM são definidas usando sistemas de prova interativa. ALL é a classe de todos os problemas de decisão.
Teoremas de hierarquia |
Para as classes de complexidade definidas desta forma, é desejável provar que relaxar os requisitos em função (digamos) do tempo de computação realmente define um conjunto maior de problemas. Em particular, embora DTIME(n) esteja contido em DTIME(n2), seria interessante saber se a inclusão é estrita. Para requisitos de tempo e de espaço, a resposta a tais perguntas é dada pelo teorema de hierarquia para a complexidade de tempo e pelo teorema de hierarquia para a complexidade de espaço, respectivamente. Eles são chamados teoremas de hierarquia porque induzem uma hierarquia adequada sobre as classes definidas, restringindo os respectivos recursos. Assim, existem pares de classes de complexidade tal que uma está propriamente contida na outra. Depois de ter deduzido assim as relações de pertinência estrita de conjuntos, podemos continuar a fazer declarações quantitativas sobre quanto mais tempo adicional ou espaço é necessário para aumentar o número de problemas que podem ser resolvidos.
Mais precisamente, o teorema de hierarquia de tempo afirma que:

O teorema de hierarquia de espaço afirma que:

Os teoremas de hierarquia de tempo e de espaço formam a base para a maioria dos resultados de separação de classes de complexidade. Por exemplo, o teorema da hierarquia de tempo nos diz que P está estritamente contida em EXPTIME, e o teorema hierarquia do espaço nos diz que L está estritamente contida em PSPACE.
Redução |
Muitas classes de complexidade são definidas usando o conceito de redução. Uma redução é uma transformação de um problema em outro problema. Ela captura a noção informal de um problema que seja pelo menos tão difícil quanto outro problema. Por exemplo, se um problema X pode ser resolvido usando um algoritmo para Y, X não é mais difícil do que Y, e dizemos que X se reduz a Y. Existem muitos tipos diferentes de redução, com base no método de redução, como reduções de Cook, reduções de Karp e reduções Levin, e no limite da complexidade das reduções, como reduções de tempo polinomial ou reduções log-space.
A redução mais comumente usada é uma redução em tempo polinomial. Isso significa que o processo de redução leva tempo polinomial. Por exemplo, o problema do quadrado de um inteiro pode ser reduzido para o problema da multiplicação de dois números inteiros. Isso significa que um algoritmo para multiplicar dois inteiros pode ser usado para o quadrado de um inteiro. De fato, isso pode ser feito dando a mesma entrada para ambas as entradas do algoritmo de multiplicação. Assim, vemos que o problema do quadrado de um inteiro não é mais difícil do que o problema da multiplicação, já que o problema do quadrado de um inteiro pode ser reduzido ao problema da multiplicação.
Isso motiva o conceito de um problema que ser difícil para uma classe de complexidade. Um problema X é difícil para uma classe de problemas C se todo problema em C pode ser reduzido a X. Assim, nenhum problema em C é mais difícil do que X, uma vez que um algoritmo para X nos permite resolver qualquer problema em C. É claro que a noção de problemas difíceis depende do tipo de redução a ser utilizado. Para as classes de complexidade maiores do que P, reduções em tempo polinomial são comumente usados. Em particular, o conjunto de problemas que são difíceis para NP é o conjunto de problemas NP-difícil.
Se um problema X está em C e é difícil para C, então diz-se que X é completo para C. Isto significa que X é o problema mais difícil em C. (Uma vez que muitos problemas poderiam ser igualmente difíceis, pode-se dizer que X é um dos os problemas mais difíceis em C.) Assim, a classe de problemas NP-completo contém os problemas mais difíceis em NP, nesse sentido eles são os mais propensos a não estarem em P. Como o problema P = NP não foi resolvido, ser capaz de reduzir um conhecido problema NP-completo, Π2, para outro problema, Π1, indicaria que não há nenhuma solução conhecida em tempo polinomial para Π1. Isso ocorre porque uma solução em tempo polinomial para Π1 renderia uma solução em tempo polinomial para Π2. Da mesma forma que todos os problemas NP podem ser reduzidos ao conjunto, encontrar um problema NP-completo que pudesse ser resolvido em tempo polinomial significaria que P = NP.[2]
Importantes problemas em aberto |
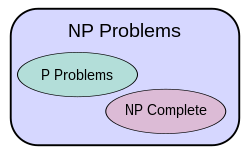
Diagrama de classes de complexidade assumindo que P ≠ NP. A existência de problemas em NP fora tanto de P quanto de NP-completo, neste caso, foi estabelecida por Ladner.[3]
O problema P versus NP |
A classe de complexidade P é muitas vezes vista como uma abstração matemática de modelagem dessas tarefas computacionais que admitem um algoritmo eficiente. Esta hipótese é chamada de tese de Cobham-Edmonds. A classe de complexidade NP, por outro lado, contém muitos problemas que as pessoas gostariam de resolver de forma eficiente, mas para os quais nenhum algoritmo eficiente é conhecido, como o problema da satisfatibilidade booleana, o problema do caminho hamiltoniano e o problema da cobertura de vértices. Como as máquinas de Turing determinística são máquinas de Turing não-determinísticas especiais, é fácil observar que cada problema em P também é membro da classe NP.
A questão de saber se P é igual a NP é uma das questões mais importantes em aberto na ciência da computação teórica por causa da gama de implicações de uma solução.[2] Se a resposta for sim, para muitos problemas importantes pode ser mostrado que há soluções mais eficientes para eles. Estes incluem vários tipos de problemas de programação inteira em investigação operacional, muitos problemas na área de logística, previsão da estrutura de proteínas na biologia,[4] e capacidade de encontrar provas formais de teoremas da matemática pura.[5] O problema P versus NP é um dos Problemas do Prêmio Millenium (Millenium Prize Problems) proposto pelo Instituto Clay de Matemática (Clay Mathematics Institute). Existe um prêmio de um milhão de dólares para resolver o problema.[6]
Problemas em NP que não se sabe se pertencem a P ou a NP-completo |
Foi mostrado por Ladner que, se P ≠ NP, então existem problemas em NP que não estão nem em P nem em NP-completo.[3] Tais problemas são chamados de problemas NP-intermediário. O problema do isomorfismo de grafos, o problema do logaritmo discreto e o problema de fatoração de inteiros são exemplos de problemas que acredita-se que sejam NP-intermediário. Eles são alguns dos muito poucos problemas NP que não se sabe se estão em P ou em NP-completo.
O problema do isomorfismo de grafos é o problema computacional para determinar se dois grafos finitos são isomorfos. Um importante problema não resolvido na teoria da complexidade é se o problema do isomorfismo de grafos está em P, NP-completo, ou NP-intermediário. A resposta não é conhecida, mas acredita-se que o problema não seja, pelo menos, NP-completo.[7] Se o isomorfismo de grafos for NP-completo, a hierarquia de tempo polinomial colapsa para seu segundo nível.[8] Uma vez que acredita-se veemente que a hierarquia polinomial não colapse para nenhum nível finito, acredita-se que o isomorfismo de grafos não seja NP-completo. O melhor algoritmo para este problema, de acordo com Laszlo Babai e Eugene Luks tem tempo de execução 2O(√(n log(n))) para grafos com n vértices.
O problema da fatoração de inteiros é o problema computacional para determinar a fatoração prima de um dado inteiro. Formulado como um problema de decisão, é o problema para decidir se a entrada tem um fator menor que k. Nenhum algoritmo de fatoração de inteiro eficiente é conhecido, e este fato é a base de vários sistemas criptográficos modernos, como o algoritmo RSA. O problema da fatoração de inteiros está em NP e em co-NP (e até mesmo em UP e co-UP [9]). Se o problema é NP-completo, a hierarquia de tempo polinomial colapsará para seu primeiro nível (ou seja, NP será igual a co-NP). O melhor algoritmo conhecido para fatoração de inteiros é o GNFS (general number field sieve), que leva tempo O(e(64/9)1/3(n.log 2)1/3(log (n.log 2))2/3) para fatorar um inteiro de n-bit. No entanto, o melhor algoritmo quântico conhecido para este problema, o algoritmo de Shor, é executado em tempo polinomial. Infelizmente, este fato não diz muito sobre onde está o problema com relação a classes de complexidade não-quântica.
Separações entre outras classes de complexidade |
Muitas classes de complexidade conhecidas são suspeitas de não serem iguais, mas isso não foi provado. Por exemplo, P ⊆ NP ⊆ PP ⊆ PSPACE, mas é possível que P = PSPACE. Se P não for igual a NP, então P não será igual à PSPACE também. Uma vez que existem muitas classes de complexidade conhecidas entre P e PSPACE, tais como RP, BPP, PP, BQP, MA, PH, etc, é possível que todas estas classes de complexidade colapsem para uma única classe. Provar que qualquer uma destas classes não são iguais seria um grande avanço na teoria da complexidade.
Na mesma linha, co-NP é a classe que contém os problemas do complemento (ou seja, problemas com as respostas sim / não invertidas) dos problemas NP. Acredita-se [10] que NP não seja igual a co-NP, no entanto, ainda não foi comprovado. Tem sido mostrado que, se essas duas classes de complexidade não são iguais, então P não é igual a NP.
Da mesma forma, não se sabe se L (o conjunto de todos os problemas que podem ser resolvidos no espaço logarítmico) está contido estritamente em P ou é igual a P. Novamente, existem muitas classes de complexidade entre elas, tais como NL e NC, e não se sabe se elas são classes iguais ou distintas.
Suspeita-se que P e BPP sejam iguais. No entanto, é um problema em aberto, no momento, se BPP = NEXP.
Intratabilidade |
Problemas que podem ser resolvidos na teoria (por exemplo, dado um tempo infinito), mas que na prática levam muito tempo para as suas soluções sejam úteis, são conhecidos como problemas intratáveis.[11] Na teoria da complexidade, os problemas que não apresentam soluções em tempo polinomial são considerados intratáveis por mais pequenas que sejam suas entradas. Na verdade, a tese de Cobham-Edmonds afirma que apenas os problemas que podem ser resolvidos em tempo polinomial podem ser computados de maneira factível por algum dispositivo computacional. Problemas que são conhecidos por serem intratáveis neste sentido incluem aqueles que são EXPTIME-difícil. Se NP não é o mesmo que P, então os problemas NP-completo são também intratáveis neste sentido. Para ver porque algoritmos de tempo exponencial podem ser impraticáveis, considere um programa que faz 2n operações antes de parar. Para n pequeno, digamos 100, e assumindo, por exemplo, que o computador faz 1012 operações por segundo, o programa seria executado por cerca de 4 × 1010 anos, que é aproximadamente a idade do universo. Mesmo com um computador muito mais rápido, o programa só seria útil para casos muito pequenos e, nesse sentido, a intratabilidade de um problema é um tanto independente do progresso tecnológico. No entanto, um algoritmo de tempo polinomial não é sempre prático. Se seu tempo de execução é, digamos "n"15, não é razoável considerá-lo eficiente e ainda é inútil, salvo em casos de pequeno porte.
O que intratabilidade significa na prática está aberto em debate. Dizer que um problema não está em P não implica que todos os grandes casos de problemas são difíceis ou até mesmo que a maioria deles são. Por exemplo, o problema da decisão na Aritmética de Presburger tem demonstrado não estar em P, ainda foram escritos algoritmos que resolvem o problema em tempos razoáveis na maioria dos casos. Da mesma forma, os algoritmos podem resolver o problema da mochila NP-completo em uma ampla faixa de tamanhos em menos que o tempo quadrático e resolvedores de SAT rotineiramente lidam com grandes instâncias do problema de satisfatibilidade booleana NP-completo.
Teoria da complexidade contínua |
A teoria da complexidade contínua pode se referir à teoria da complexidade dos problemas que envolvem funções contínuas que são aproximadas por discretizações, como estudado em análise numérica. Uma abordagem para a teoria da complexidade da análise numérica [12] é a complexidade baseada em informação (IBC).
A teoria da complexidade contínua também pode se referir à teoria da complexidade do uso da computação analógica, que utiliza sistemas dinâmicos contínuos e equações diferenciais.[13]A teoria de controle pode ser considerada uma forma de computação e equações diferenciais são usadas na modelagem de sistemas de tempo contínuo e híbridos de tempo discreto-contínuo.[14]
História |
Antes de a pesquisa propriamente dita explicitamente dedicada à complexidade dos problemas algorítmicos começar, os numerosos fundamentos foram estabelecidos por vários pesquisadores. O mais influente entre estes foi a definição das máquinas de Turing por Alan Turing em 1936, que acabou por ser uma noção muito robusta e flexível de computador.
Fortnow & Homer (2003) datam o início dos estudos sistemáticos em complexidade computacional com o importante artigo "On the Computational Complexity of Algorithms" de Juris Hartmanis e Richard Stearns (1965), que estabeleceu as definições de complexidade de tempo e de espaço e provou os teoremas de hierarquia.
De acordo com Fortnow & Homer (2003), trabalhos anteriores que estudaram problemas solucionáveis por máquinas de Turing com recursos específicos limitados inclui a definição de John Myhill de autômatos linearmente limitados (Myhill 1960), o estudo de Raymond Smullyan sobre conjuntos rudimentares (1961), assim como o artigo de Hisao Yamada [15] sobre computação em tempo real (1962). Um pouco mais cedo, Boris Trakhtenbrot (1956), um pioneiro no campo da URSS, estudou outra medida específica de complexidade.[16] Como lembra ele:
Contudo, [meu] interesse inicial [na teoria dos autômatos] era cada vez mais posto de lado em detrimento à complexidade computacional, uma excitante fusão de métodos combinatoriais, herdada da teoria da comutação, com o arsenal conceitual da teoria de algoritmos. Essas ideias me ocorreram antes, em 1955, quando eu cunhei o termo "função de sinalização", que hoje é comumente conhecido como "medida de complexidade".
—Boris Trakhtenbrot
From Logic to Theoretical Computer Science – An Update. In: Pillars of Computer Science, LNCS 4800, Springer 2008.
Em 1967, Manuel Blum desenvolveu uma teoria da complexidade axiomática com base em seus axiomas e provou um resultado importante, o então chamado, teorema da aceleração de Blum (speed-up theorem). O campo realmente começou a florescer quando o pesquisador norte-americano Stephen Cook e, trabalhando independentemente, Leonid Levin na URSS, provaram que existem importantes problemas praticáveis que são NP-completos. Em 1972, Richard Karp partiu desta ideia e deu um salto à frente com seu artigo histórico, "Reducibility Among Combinatorial Problems", no qual ele mostrou que 21 diferentes problemas de combinatória e problemas teóricos de grafos, famosos por sua intratabilidade computacional, são NP-completos.[17]
Ver também |

- Problemas em aberto da ciência da computação
- Categoria:Teoria da computação
- Lista de termos relacionados aos algoritmos e estruturas de dados
Notas |
↑ Escolha uma cidade, e pegue todas as ordenações possíveis das outras 14 cidades. Depois divida por dois, porque não importa em qual direção pelo tempo elas vêm uma após a outra: 14 / 2 = 43.589.145.600.
Referências
↑ Veja Arora & Barak 2009, Chapter 1: The computational model and why it doesn't matter
↑ ab Veja Sipser 2006, Chapter 7: Time complexity
↑ ab Ladner, Richard E. (1975), «On the structure of polynomial time reducibility» (PDF), Journal of the ACM (JACM), 22 (1): 151–171, doi:10.1145/321864.321877.
↑ Berger, Bonnie A.; Leighton, T (1998), «Protein folding in the hydrophobic-hydrophilic (HP) model is NP-complete», Journal of Computational Biology, 5 (1): 27–40, PMID 9541869, doi:10.1089/cmb.1998.5.27.|number=e|issue=redundantes (ajuda)
↑ Cook, Stephen (2000), The P versus NP Problem (PDF), Clay Mathematics Institute, consultado em 18 de outubro de 2006.
↑ Jaffe, Arthur M. (2006), «The Millennium Grand Challenge in Mathematics» (PDF), Notices of the AMS, 53 (6), consultado em 18 de outubro de 2006.
↑ Arvind, Vikraman; Kurur, Piyush P. (2006), «Graph isomorphism is in SPP», Information and Computation, 204 (5): 835–852, doi:10.1016/j.ic.2006.02.002.
↑ Uwe Schöning, "Graph isomorphism is in the low hierarchy", Proceedings of the 4th Annual Symposium on Theoretical Aspects of Computer Science, 1987, 114–124; also: Journal of Computer and System Sciences, vol. 37 (1988), 312–323
↑ Lance Fortnow. Computational Complexity Blog: Complexity Class of the Week: Factoring. September 13, 2002. http://weblog.fortnow.com/2002/09/complexity-class-of-week-factoring.html
↑ Boaz Barak's course on Computational Complexity Lecture 2
↑ Hopcroft, J.E., Motwani, R. and Ullman, J.D. (2007) Introduction to Automata Theory, Languages, and Computation, Addison Wesley, Boston/San Francisco/New York (page 368)
↑ Complexity Theory and Numerical Analysis, Steve Smale, Acta Numerica, 1997 - Cambridge Univ Press
↑ A Survey on Continuous Time Computations, Olivier Bournez, Manuel Campagnolo, New Computational Paradigms. Changing Conceptions of What is Computable. (Cooper, S.B. and L{"o}we, B. and Sorbi, A., Eds.). New York, Springer-Verlag, pages 383-423. 2008
↑ Computational Techniques for the Verification of Hybrid Systems, Claire J. Tomlin, Ian Mitchell, Alexandre M. Bayen, Meeko Oishi, Proceedings of the IEEE, Vol. 91, No. 7, July 2003.
↑ Yamada, Hisao (1 de dezembro de 1962). «Real-Time Computation and Recursive Functions Not Real-Time Computable». IRE Transactions on Electronic Computers. EC-11 (6): 753-760. ISSN 0367-9950. doi:10.1109/TEC.1962.5219459
↑ Trakhtenbrot, B.A.: Signalizing functions and tabular operators. Uchionnye Zapiski
Penzenskogo Pedinstituta (Transactions of the Penza Pedagogoical Institute) 4, 75–87 (1956) (in Russian)
↑ Richard M. Karp (1972), «Reducibility Among Combinatorial Problems» (PDF), in: R. E. Miller and J. W. Thatcher (editors), Complexity of Computer Computations, New York: Plenum, pp. 85–103
Bibliografia |
Sanjeev Arora, Boaz Barak, Sanjeev; Barak, Boaz (2009), Computational Complexity: A Modern Approach, ISBN 978-0-521-42426-4, Cambridge|last1=e|author=redundantes (ajuda)
Downey, Rod; Fellows, Michael (1999), Parameterized complexity, Berlin, New York: Springer-Verlag
Du, Ding-Zhu; Ko, Ker-I (2000), Theory of Computational Complexity, ISBN 978-0-471-34506-0, John Wiley & Sons A referência emprega parâmetros obsoletos|coauthors=(ajuda); Parâmetro desconhecido|country=ignorado (ajuda)
Goldreich, Oded (2008), Computational Complexity: A Conceptual Perspective, Cambridge University Press
van Leeuwen, Jan, ed. (1990), Handbook of theoretical computer science (vol. A): algorithms and complexity, ISBN 978-0-444-88071-0, MIT Press
Papadimitriou, Christos (1994), Computational Complexity, ISBN 0201530821 1st ed. , Addison Wesley
Sipser, Michael (2006), Introduction to the Theory of Computation, ISBN 0534950973 2nd ed. , USA: Thomson Course Technology
- Predefinição:Garey-Johnson
Surveys |
Khalil, Hatem; Ulery, Dana (1976), A Review of Current Studies on Complexity of Algorithms for Partial Differential Equations, ACM '76 Proceedings of the 1976 Annual Conference, doi:10.1145/800191.805573
Cook, Stephen (1983), «An overview of computational complexity», ACM, Commun. ACM, ISSN 0001-0782, 26 (6): 400–408, doi:10.1145/358141.358144
Fortnow, Lance; Homer, Steven (2003), «A Short History of Computational Complexity» (PDF), Bulletin of the EATCS, 80: 95–133
Mertens, Stephan (2002), «Computational Complexity for Physicists», Piscataway, NJ, USA: IEEE Educational Activities Department, Computing in Science and Engg., ISSN 1521-9615, 4 (3): 31–47, arXiv:cond-mat/0012185 , doi:10.1109/5992.998639 Parâmetro desconhecido
, doi:10.1109/5992.998639 Parâmetro desconhecido |unused_data=ignorado (ajuda)
Ligações externas |
- The Complexity Zoo


